第六章:Spring Cloud Sleuth
Adrian Cole, Spencer Gibb, Marcin Grzejszczak, Dave Syer Brixton.SR6 Spring cloud Sleuth为Spring cloud实现了分布式的日志追踪解决方案。
专业术语
Spring cloud Sleuth借用了Dapper’s的术语。 Span:最小工作单元。例如,发送一个rpc远程进程调用请求就是一个新的span,对rpc请求的响应也是一样。span是唯一的64位的span id和另一个64位包含了span的跟踪日志id区分。Spans还有其他的数据,例如描述,标注了时间的事件,键值注解(标签),span id,进程id(通常是ip地址)。
spans的开始,结束,会保持整个时间轴上的所有信息。一旦你创建了一个span,你必须在未来的某个时间点上停止它。
初始化的span开始日志记录的时候被称作
root span。span的id和日志id的值是相等的。
Trace:一系列的spans构成了一个树状结构。例如,你在运行一个分布式的大数据存储,一条日志记录可以通过put请求形成。
Annotation:用来及时记录事件的存在,有些重要的注解用来定义请求的开始和结束:
cs - Client Request - 客户端发送了一个请求。这个注解描述一个span的开始。
sr - Server Received - 服务端接收到了请求,并开始去处理请求。从客户端请求发出后到一个这样的服务端接受事件之间,表示网络延迟时间。
ss - Server Sent - 标识为请求处理完成(开始对客户端发送出响应)。从这个时间点到服务端接受到请求之间,表示服务端需要处理请求的时间。
cr - Client Received - 表示span的结束。客户端已经从服务端成功的接受到请求了。从这个时间点到服务端响应之间,表示客户端从服务端接受相应需要的时间。
通过Zipkin展示span和跟踪日志是什么:
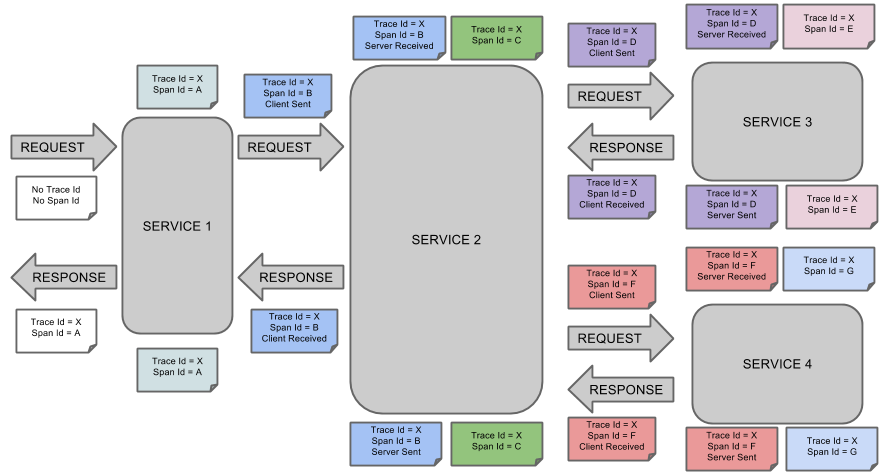 每种颜色的说明标识一个span(从A到G)。如果你有一下说明:
每种颜色的说明标识一个span(从A到G)。如果你有一下说明:
Trace Id = X
Span Id = D
Client Sent
这表示跟踪日志的id是X,Span的id是D,它发出了一个客户端请求。
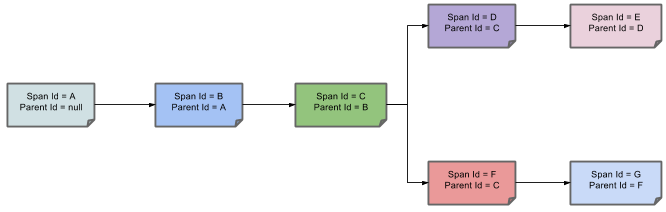
一个父子关系的可以展示成这样:
目的
以下部分已上图为例说明。
用Zipkin做分布日志跟踪
尽管有10个spans。如果你用Zipkin中跟踪记录,你会看到以下数字:
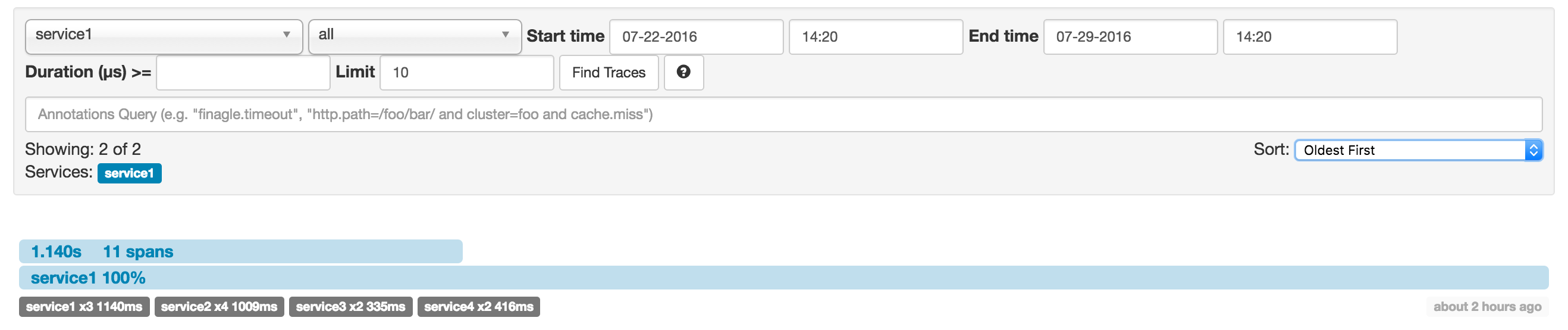 然而当我们看某个日志追踪的话,你可以看到7个span。
然而当我们看某个日志追踪的话,你可以看到7个span。
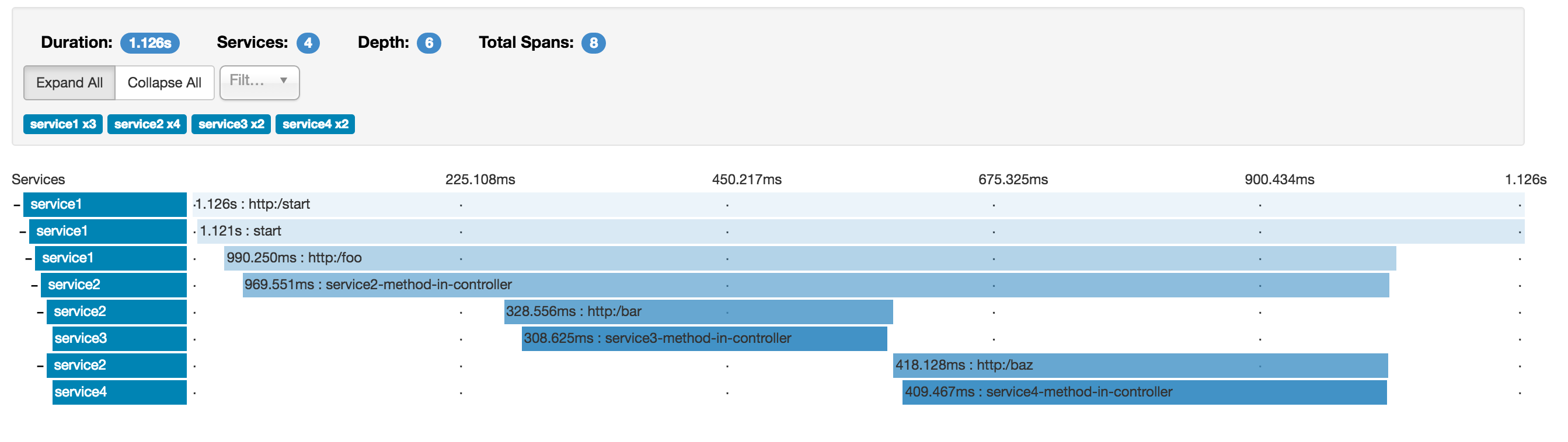
注意:当你看到某个日志追踪的话,你会看到合并的span。这意味着,如果我们通知Zipkin收到了服务端接收到请求和服务端发出响应 或者客户端接收到请求和客户端发出请求 这样的2个span,会被展示在一个span里面。
这幅图形化展示Span和Trace你可以看到20个不同颜色的标签。Zipkin接收到的10个span里发生了什么?
- 2个A 标签表示span的开始和结束。
- 4个B 标签实际上有4个不同注解的单个span。然而这个span包含两个单独的实例,一个是来自service1的,另一个是来自service2的。因此实际上会有2个span发送到Zipkin中,并在那合并。
- 2个C 标签表示span的开始和结束。一个即将关闭的span被发送到Zipkin中。
- 4个D 标签实际上有4个不同注解的单个span。然而这个span包含两个单独的实例,一个是来自service2的,另一个是来自service3的。因此实际上会有2个span发送到Zipkin中,并在那合并。
- 2个E 标签表示span的开始和结束。一个即将关闭的span被发送到Zipkin中。
- 4个B 标签实际上有4个不同注解的单个span。然而这个span包含两个单独的实例,一个是来自service2的,另一个是来自service4的。因此实际上会有2个span发送到Zipkin中,并在那合并。
- 2个G 标签表示span的开始和结束。一个即将关闭的span被发送到Zipkin中。
因此,A 1个span,B 2个span,C 1个span,D 2个span,E 1个span,F 2个span,G 1个span,总共10个span。

Zipkin中的依赖图看起来会像这样:
日志关系整理
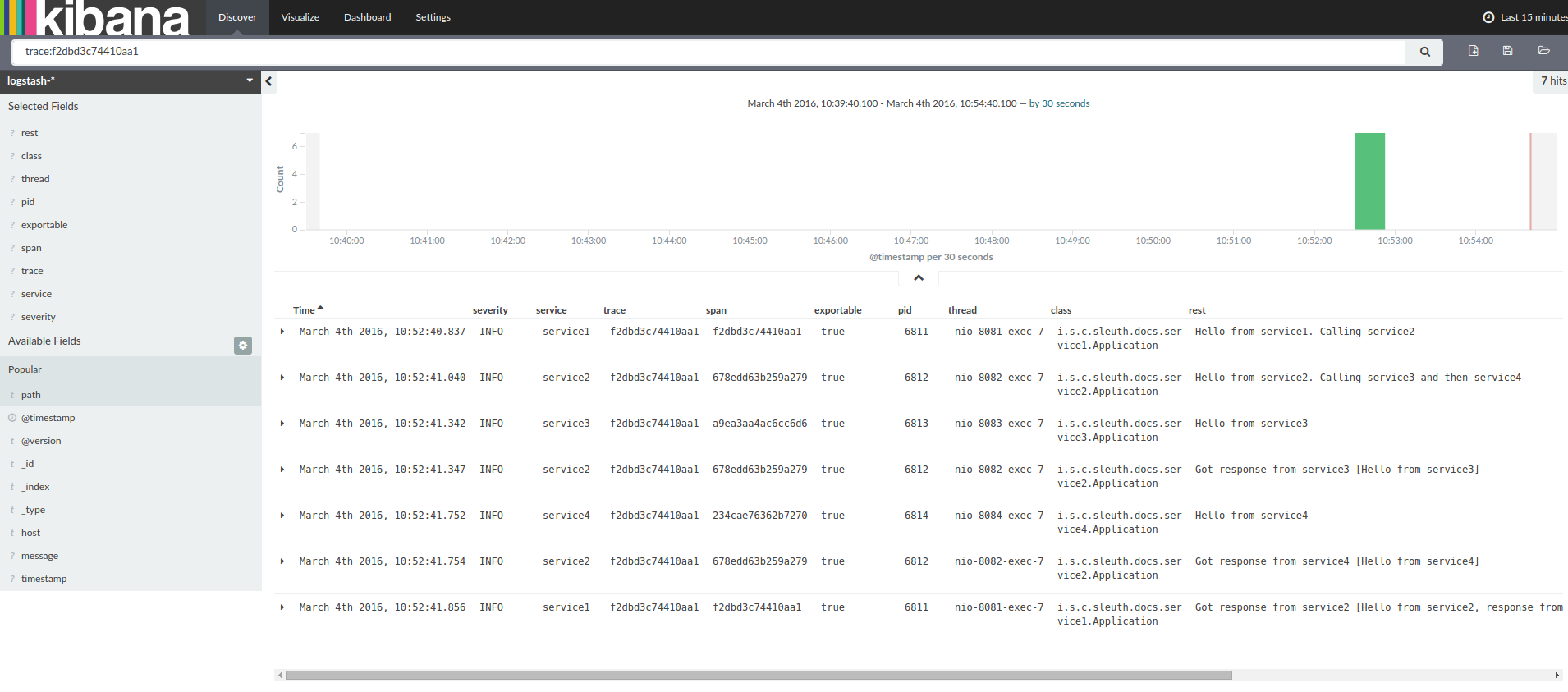
当你从4个应用中过滤日志id等于2485ec27856c56f4的日志,可能得到以下结果:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
如果你用日志整合工具例如Kibana, Splunk,...之类的。可以发生的事件进行排序。Kibana的例子看上去这样的:
如果你想用Logstash,这里是需要用Logstash的Grok正则:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
注意:如果想将Grok和Cloud Foundry的日志一起用的话,你需要用这个正则:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
和Logstash一起用json Logback
通常不太会把日志存放在文本文件中,而是Logstash可以立即使用的json格式。想要做到那个的话,你需要这样做(为了更好的可读性,通过groupId:artifactId:version说明的方式去添加依赖)
依赖设置
- 确认classpath下有Logback(ch.qos.logback:logback-core)。
- 添加Logstash Logback encode例如4.6的版本:
net.logstash.logback:logstash-logback-encoder:4.6
Logback设置 以下可以看到Logback的配置(在logback-spring.xml文件中):
- json格式的应用日志在build/${spring.application.name}.json文件中
- 有两个日志输入的地方(控制台和标准的日志文件)
- 有和之前呈现的那部分一样的日志格式
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${springAppName:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>INFO</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<!--<appender-ref ref="console"/>-->
<appender-ref ref="logstash"/>
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>
注意: 如果你自定义的logback-spring.xml,在bootstrap中需要传入spring.application.name替换应用的属性文件。否则你自定义的logback文件不能完整的读取所有的属性。
添加到项目中
只用Sleuth(日志的关系整理)
如果你只想使用Spring Cloud Sleuth,不用Zipkin的整合,只要添加spring-cloud-starter-sleuth模块到你的项目中去。
Maven<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-starter-sleuth的依赖
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-starter-sleuth的依赖
通过http将Sleuth和Zipkin一起使用
如果你既用Sleuth也用Zipkin需要添加spring-cloud-starter-zipkin依赖。
Maven<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-starter-zipkin的依赖
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-starter-zipkin的依赖
通过Spring Cloud Stream将Sleuth和Zipkin一起使用
如果你既用Sleuth也用Zipkin需要添加spring-cloud-sleuth-strea依赖。
Maven<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- EXAMPLE FOR RABBIT BINDING -->
<dependency> (4)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-starter-zipkin的依赖
- 添加spring-cloud-starter-sleuth-的依赖,这种方式,所有需要的依赖都会被下载
添加绑定(例如rabbit绑定),告诉Spring Cloud Stream,应该绑定到哪
Gradle
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-sleuth-stream" (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth" (3)
// Example for Rabbit binding
compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit" (4)
}
Spring Cloud Sleuth Stream Zipkin结合
如果你想要Spring Cloud Sleuth Stream Zipkin结合使用,需要添加spring-cloud-sleuth-zipkin-stream依赖。
Maven<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Brixton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- EXAMPLE FOR RABBIT BINDING -->
<dependency> (4)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-sleuth-zipkin-stream的依赖
- 添加spring-cloud-sleuth-zipkin-stream-的依赖,这种方式,所有需要的依赖都会被下载
- 添加绑定(例如rabbit绑定),告诉Spring Cloud Stream,应该绑定到哪
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-sleuth-zipkin-stream" (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth" (3)
// Example for Rabbit binding
compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit" (4)
}
- 为了不用自己选择版本的话,可以通过BOM管理你的依赖
- 添加spring-cloud-sleuth-zipkin-stream的依赖
- 添加spring-cloud-sleuth-zipkin-stream-的依赖,这种方式,所有需要的依赖都会被下载
添加绑定(例如rabbit绑定),告诉Spring Cloud Stream,应该绑定到哪
然后只需要在主函数上添加@EnableZipkinStreamServer注解。
package example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
@SpringBootApplication
@EnableZipkinStreamServer
public class ZipkinStreamServerApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(ZipkinStreamServerApplication.class, args);
}
}
特性
- 添加跟踪和span的id到Slf4J MDC,就可以从日志结果中获取任意的跟踪和span。日志示例:
注意:[appname,traceId,spanId,exportable]是MDC的各个字段。2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...
spanId 发生的某一特定操作id appname 记录span日志的应用的名称 traceId 包含span的延迟图的id exportable 日志能否被导出到Zipkin。什么时候你会希望span不被导出?在一个span里你想包装某些操作,并希望只写到日志中。
- 通过常用的分布式日志数据模型提供抽象结果:traces, spans (forming a DAG), annotations, key-value annotations。基于HTrace,但基于Zipkin(Dapper)
- Sleuth记录了时间消息,帮助延迟分析。通过Sleuth,能精确的定位你的应用中发生延迟的地方。Sleuth被实现成不要记录太多的日志,因而不会导致系统崩溃。 汇报:in-band调用图数据,以及其余的out-of-band数据。 包含http的几层传输协议。 包含管理大小的简单策略 可以报告到Zipkin中用以查询和查看。
- 测量spring应用的进出口(servlet filter, async endpoints, rest template, scheduled actions, message channels, zuul filters, feign client)
- Sleuth包含默认的逻辑添加一个跨http后者消息绑定的跟踪记录。例如,http通过Zipkin兼容的http请求头消息汇报。这个汇报用默认定义的逻辑或者自定义的SpanInjector和SpanExtractor的实现。
- 提供接受或者丢弃的sapn的简单metrics监控。
- 如果用spring-cloud-sleuth-zipkin,应用会生成并收集兼容Zipkin的跟踪。默认情况下,它通过http发送到本地的Zipkin服务上(9411端口)上。用
spring.zipkin.baseUrl配置服务的地址。 - 如果用spring-cloud-sleuth-stream,应用会通过Spring Cloud Stream生成并收集跟踪.你的应用会自动成为跟踪消息服务器的生产者,通过你的代理发送(RabbitMQ, Apache Kafka, Redis)。
重要:如果你想使用Zipkin或者Stream,用
spring.sleuth.sampler.percentage配置需要导出的span的百分比(默认0.1,10%)。否则你可能并不认为Sleuth在工作,因为它不生成任何span 注意:SLF4J MDC一直发出跟踪并会被logback用户会在日志中立即发现跟踪和日志id,就以上的例子而言。其他的日志系统需要配置她们自己的格式去获取结果。默认的logging.pattern.level设置为%clr(%5p) %clr([${spring.application.name:},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]){yellow}(这是spring boot对logback 用户的特性)。这意味着如果你不用SLF4J,不用这种模式不会自动被自动应用。
基础框架
在分布式追踪日志数据量可能会非常大,应此抽样显得十分重要(一般我们不需要导出所有的span到一张图里,查看正在发生的的事情)。Spring Cloud Sleuth有一个Sampler取样策略,可以实现这个策略控制抽样的算法。这些抽样不会把生成的相关的span id断开,但是会切断一些标签,关联的事件,以及导出。默认你会得到这样的策略,激活状态的span会被继续跟踪,但是新的span会被标记不被导出。如果你所有的应用运行这个策略,你会在日志中看到跟踪,而不在任何一个远程的数据库中。测试用的话,默认的配置足够了,这应该是所需要的如果只用日志的话(例如ELK日志整理器)。如果你导出的span数据到Zipkin或者Spring Cloud Stream,还会有一个AlwaysSampler抽样会导出所有的日志,以及一个PercentageBasedSampler会抽样指定的比例的span。
注意:如果使用spring-cloud-sleuth-zipkin或者spring-cloud-sleuth-stream,PercentageBasedSampler是默认的抽样策略。可以通过spring.sleuth.sampler.percentage配置导出的比例。
可以简单的定义一个对象,来安装一个抽样:
@Bean
public Sampler defaultSampler() {
return new AlwaysSampler();
}
基础框架
Spring Cloud Sleuth自动添加了spring应用的工具,不必再激活。根据相应的技术栈通过许多技术加入了这些工具。例如servlet web应用,我们使用filter,对于spring的整合,我们用ChannelInterceptors。
你可以在span的标签内自定义的一些键。为了限制span数据量,一个http请求会被许多有用的基础数据标识,例如状态码,域名,url路径。你可以通过spring.sleuth.keys.http.headers配置添加请求头消息(头消息列表)。
注意:记住只有当Sampler抽样允许的时候,span标签才会被收集并被导出(默认情况下不会,因此不会没有做任何配置的情况下意外发生收集太多的数据)。
目前Spring Cloud Sleut的基础配置的饥渴,意味着,我们在线程之间传递跟踪的上下文。即使sleuth不导出数据到跟踪系统中,我们也捕获时间线上的事件。这一特性未来会被lazy模式取代。
span的生命周期
你可以通过org.springframework.cloud.sleuth.Tracer的接口对span进行以下几种操作:
start - 当你开始的时候,span的名称会被赋值,并且开始时间也会被记录下。
close - 当span结束的时候,(结束时间也会被记录下)并且如果span可以被导出的话,它也会被选择导出到Zopkin。span也会从当前的线程中移除。
continue - 当一个span的新示例创建的时候,由于它是一个拷贝,相当于之前span的延续。
detach - span没有停止或者结束。只是从当前线程中移除。
create with explicit parent - 你可以创建一个新的span,并指定到父span中。
Spring会为你创建Tracer。想要使用的话,你需要做的就是自动加载它。
span的创建和结束
你可以用Tracer接口手动创建span。
// Start a span. If there was a span present in this thread it will become
// the `newSpan`'s parent.
Span newSpan = this.tracer.createSpan("calculateTax");
try {
// ...
// You can tag a span
this.tracer.addTag("taxValue", taxValue);
// ...
// You can log an event on a span
newSpan.logEvent("taxCalculated");
} finally {
// Once done remember to close the span. This will allow collecting
// the span to send it to Zipkin
this.tracer.close(newSpan);
}
这个例子中我们可以看到如何创建一个span实例。假设当前线程里面已经有一个span了,它会成为这个span的父节点。
重要通知:创建了span以后一定要清楚!如果你想发送到Zipkin中,也不要忘记关闭该span。
span的继续
有时候你不想创建一个新的span,只希望继续原来某个。这种情形的例子可能是(当然这取决于用例):
- AOP - 如果在某个切面之前已经创建了一个span,你应该不希望再创建一个了。
- Hystrix - 执行一个Hystrix命令很可能像是当前进程中的一部分逻辑。实际上,这是一个技术细节,没必要单独反映到跟踪结果里面。
延续的span和被延续的span是equal的。
Span continuedSpan = this.tracer.continueSpan(spanToContinue);
assertThat(continuedSpan).isEqualTo(spanToContinue);
可以用Tracer继续span。
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X
Span continuedSpan = this.tracer.continueSpan(initialSpan);
try {
// ...
// You can tag a span
this.tracer.addTag("taxValue", taxValue);
// ...
// You can log an event on a span
continuedSpan.logEvent("taxCalculated");
} finally {
// Once done remember to detach the span. That way you'll
// safely remove it from the current thread without closing it
this.tracer.detach(continuedSpan);
}
重要提示:创建span之后,不要忘了清除!也不要忘记在一个线程(例如x线程)中工作完成后取消挂载span,而其他线程(例如y线程)还在等着它结束。span在这些线程x,线程y完成工作之后,应该被取消挂载。当结果被收集到的时候,线程x应该被关闭。
指定的父span中创建一个新的span
有很大的可能你想在指定的父span下,创建一个新的span。假设父span在一个线程中,你需要在新的线程里创建线程。Tracer接口下startSpan方法应该就是你要找的:
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X. `initialSpan` will be the parent
// of the `newSpan`
Span newSpan = this.tracer.createSpan("calculateCommission", initialSpan);
try {
// ...
// You can tag a span
this.tracer.addTag("commissionValue", commissionValue);
// ...
// You can log an event on a span
newSpan.logEvent("commissionCalculated");
} finally {
// Once done remember to close the span. This will allow collecting
// the span to send it to Zipkin. The tags and events set on the
// newSpan will not be present on the parent
this.tracer.close(newSpan);
}
重要提示:一定要记得关闭span,在创建一个span之后。否则在你的日志里面你会看到很多告警类似你尝试在当前线程里关闭在另外一个线程里的span。更严重的是,你的span由于无法关闭而没法收集到Zipkin里。
命名span
为span命名很有讲究。span名可以描述一个操作。名字应该精短(例如,不要不含id)。 因此许多的结构在用,这些名字很有艺术性:
controller-method-name 控制器的某个方式接受到请求
async 由于某些异步操作通过封装的调用和运行
@Scheduled 注解的方法会返回类的简称
幸运的是,可以为异步的过程提供严格的命名。
@SpanName注解
可以用@SpanName注解严格的指定span的名称。
@SpanName("calculateTax")
class TaxCountingRunnable implements Runnable {
@Override public void run() {
// perform logic
}
}
这种情况下,如果我们这么处理:
Runnable runnable = new TraceRunnable(tracer, spanNamer, new TaxCountingRunnable());
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();
这个span的名称会是calculateTax。
toString()方法
很少的情况下单独为Runnable或者Callable创建类。典型的一种情况是我们创建一个匿名实例。你无法通过添加注解重写,没有@SpanName注解,我们可以检查下有没有自定义的toString()方法。
因此,执行这样的代码:
Runnable runnable = new TraceRunnable(tracer, spanNamer, new Runnable() {
@Override public void run() {
// perform logic
}
@Override public String toString() {
return "calculateTax";
}
});
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();
会创建一个叫calculateTax的span。
自定义
幸亏有SpanInjector和SpanExtractor,可以自定义span的创建和汇报:
当前有2中内置的方式在进程之间传递追踪信息:
- 通过spring的整合
- 通过http 这些span的id是从兼容Zipkin的头消息(消息,或者头信息)中获取的,用以开始或者接入已经存在的跟踪。跟踪消息绑定到对外的请求,因此其他的网络中才能获取他们。
Spring的整合
Spring整合,有很多对象用来从Message创造span,并用MessageBuilder填充跟踪信息。
@Bean
public SpanExtractor<Message> messagingSpanExtractor() {
...
}
@Bean
public SpanInjector<MessageBuilder> messagingSpanInjector() {
...
}
你可以通过@Primary注解添加到自定义的对象上重写。
http
http的方式,有很多对象用来从HttpServletRequest创造span,并用HttpServletResponse填充跟踪信息。
@Bean
public SpanExtractor<HttpServletRequest> httpServletRequestSpanExtractor() {
...
}
@Bean
public SpanInjector<HttpServletResponse> httpServletResponseSpanInjector() {
...
}
你可以通过@Primary注解添加到自定义的对象上重写。
示例
假设你没有标准的Zipkin,只有兼容跟踪信息的HTTP头信息名称。
- 对于跟踪id - correlationId
- 对于span id - mySpanId
这是一个SpanExtractor的例子:
static class CustomHttpServletRequestSpanExtractor
implements SpanExtractor<HttpServletRequest> {
@Override
public Span joinTrace(HttpServletRequest carrier) {
long traceId = Span.hexToId(carrier.getHeader("correlationId"));
long spanId = Span.hexToId(carrier.getHeader("mySpanId"));
// extract all necessary headers
Span.SpanBuilder builder = Span.builder().traceId(traceId).spanId(spanId);
// build rest of the Span
return builder.build();
}
}
以下情况SpanInjector会被创建
static class CustomHttpServletResponseSpanInjector
implements SpanInjector<HttpServletResponse> {
@Override
public void inject(Span span, HttpServletResponse carrier) {
carrier.addHeader("correlationId", Span.idToHex(span.getTraceId()));
carrier.addHeader("mySpanId", Span.idToHex(span.getSpanId()));
// inject the rest of Span values to the header
}
}
然后你还可以这样注册:
@Bean
@Primary
SpanExtractor<HttpServletRequest> customHttpServletRequestSpanExtractor() {
return new CustomHttpServletRequestSpanExtractor();
}
@Bean
@Primary
SpanInjector<HttpServletResponse> customHttpServletResponseSpanInjector() {
return new CustomHttpServletResponseSpanInjector();
}
在Zipkin中自定义的SA标签
有时候你需要手动创建一个span然后包装一个请求调用未工具化的外部服务。你可以通过peer.service创建一个span 标签,包含你要调用的服务的值。以下例子你可以看到调用redis的例子会被包装到这样的span里:
org.springframework.cloud.sleuth.Span newSpan = tracer.createSpan("redis");
try {
newSpan.tag("redis.op", "get");
newSpan.tag("lc", "redis");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_SEND);
// call redis service e.g
// return (SomeObj) redisTemplate.opsForHash().get("MYHASH", someObjKey);
} finally {
newSpan.tag("peer.service", "redisService");
newSpan.tag("peer.ipv4", "1.2.3.4");
newSpan.tag("peer.port", "1234");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV);
tracer.close(newSpan);
}
重要提示:记住不能同时添加peer.service标签和SA标签!你只能添加peer.service标签。
span数据作为消息
你可以通过Spring Cloud Stream累积数据并且发送出去通过添加spring-cloud-sleuth-stream jar包作为依赖,并添加频道绑定(例如为RabbitMQ添加spring-cloud-starter-stream-rabbit或者为kafka添加spring-cloud-starter-stream-kafka)。这会把你的应用转换成负载Spans类型的消息生产者。
Zipkin的消费者
有一个非常方便的注解能设置span数据的消息消费者,并推送到SpanStore中。这个应用:
@SpringBootApplication
@EnableZipkinStreamServer
public class Consumer {
public static void main(String[] args) {
SpringApplication.run(Consumer.class, args);
}
}
会监听任意协议下的Span数据,通过Spring Cloud Stream绑定(例如为RabbitMQ添加spring-cloud-starter-stream-rabbit或者为kafka添加spring-cloud-starter-stream-kafka)。如果你添加以下界面依赖:
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
那么你将有一个Zipkin服务端,在9411端口上生成界面和提供api。
默认的SpanStore是在内存中的(案例展示很好,并且能很快的运行)。想要更稳定的应用,你可以添加mysql和在classpath下spring-boot-starter-jdbc并通过配置开启JDBC SpanStore例如:
spring:
rabbitmq:
host: ${RABBIT_HOST:localhost}
datasource:
schema: classpath:/mysql.sql
url: jdbc:mysql://${MYSQL_HOST:localhost}/test
username: root
password: root
# Switch this on to create the schema on startup:
initialize: true
continueOnError: true
sleuth:
enabled: false
zipkin:
storage:
type: mysql
注意:以上消费者应用示例严格的去除了
SleuthStreamAutoConfiguration的依赖,所以它不会给自己发消息,但这是可选项(你或许要跟踪调用消费者的请求)。
Metrics度量
目前Spring Cloud Sleuth只注册了和span有关的简单metrics度量。用Spring Boot’s metrics support去计算接收到以及丢掉的span数量。每次span发送到Zipkin中,接收的span的数量会加1。如果出错,掉丢的span数量会加1。
集成
Runnable和Callable
如果你用Runnable或Callable来封装你的逻辑,在Sleuth代表里包装这些类足够了。 Runnable的例子:
Runnable runnable = new Runnable() {
@Override
public void run() {
// do some work
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceRunnable` creation with explicit "calculateTax" Span name
Runnable traceRunnable = new TraceRunnable(tracer, spanNamer, runnable, "calculateTax");
// Wrapping `Runnable` with `Tracer`. The Span name will be taken either from the
// `@SpanName` annotation or from `toString` method
Runnable traceRunnableFromTracer = tracer.wrap(runnable);
Callable的例子:
Callable<String> callable = new Callable<String>() {
@Override
public String call() throws Exception {
return someLogic();
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceCallable` creation with explicit "calculateTax" Span name
Callable<String> traceCallable = new TraceCallable<>(tracer, spanNamer, callable, "calculateTax");
// Wrapping `Callable` with `Tracer`. The Span name will be taken either from the
// `@SpanName` annotation or from `toString` method
Callable<String> traceCallableFromTracer = tracer.wrap(callable);
这种方式下,你可以保证每次执行每个span能被创建和关闭。
Hystrix
自定义并发策略
我们通过注册自定义的HystrixConcurrencyStrategy的方式,把所有的Callable实例包装到Sleuth代表中-TraceCallable。策略去开始或者继续一个span决定于,记录是在Hystrix命令之前还是之后。要禁用自定义的Hystrix并发策略,只要把spring.sleuth.hystrix.strategy.enabled设置为false。
手动命令设置
假定你有以下HystrixCommand命令:
HystrixCommand<String> hystrixCommand = new HystrixCommand<String>(setter) {
@Override
protected String run() throws Exception {
return someLogic();
}
};
为了传递一些跟踪信息,你需要把某些操作的TraceCommand包装为Sleuth一定版本的HystrixCommand命令:
TraceCommand<String> traceCommand = new TraceCommand<String>(tracer, traceKeys, setter) {
@Override
public String doRun() throws Exception {
return someLogic();
}
};
RXJava
我们注册一个自定义的RxJavaSchedulersHook把所有的Action0实例封装为Sleuth代表中-TraceAction。这个锚点开始或者继续一个span决定于,记录是在动作是在计划之前还是之后发生。要禁用自定义的RxJavaSchedulersHook,把spring.sleuth.rxjava.schedulers.hook.enabled设置为false。
你可以定义一个线程名称的正则表达式列表,过滤不想创建的span。只要用逗号,分隔这些正则表达式,设置为 spring.sleuth.rxjava.schedulers.ignoredthreads的属性。
HTTP集成
可以通过spring.sleuth.web.enabled属性设置为false,禁用这部分的特性。
HTTP过滤器
通过TraceFilter过滤的所有取样对内请求会创建span。span的名称为:http: + 请求的路径。例如。如果请求的路径是/foo/bar,名称则为http:/foo/bar。你可以通过spring.sleuth.web.skipPattern属性配置你需要忽略的URI。如果你的classpath下有ManagementServerProperties,那你的contextPath的值会被添加到忽略的表达式中。
HandlerInterceptor拦截器
由于我们希望span的名称更准确,我们使用TraceHandlerInterceptor要么包装已经存在的HandlerInterceptor,或者直接添加到HandlerInterceptors列表。TraceHandlerInterceptor会为HttpServletRequest请求添加一个特别的请求属性。如果TraceFilter没有发现这个请求属性,它会在服务端创建一个额外的span作为回馈,因此跟踪信息才能在界面完整的展示。如果发现了什么重要的部分丢失了。这种情况下,请在Spring Cloud Sleuth上提出问题。
异步的servlet支持
如果你的请求返回一个Callable或者WebAsyncTask对象,Spring Cloud Sleuth会继续已经存在的span,而不是创建一个新的。
Http客户端集成
同步Rest模板
我们通过Rest模板拦截器的注入确定所有的跟踪信息都传到请求中,每次调用都会创建新的span。当即将接受到响应的时候span被关闭。想要阻止同步Rest模板的特性,可以设置spring.sleuth.web.client.enabled为false。
重要提示:你必须把RestTemplate注册为一个对象,过滤器才能被注入。如果你用new关键字创建了RestTemplate对象,基础的工具就不会工作。
异步Rest模板
自定义工具在发出请求和接收响应的时候去创建和关闭span。你可以通过注册对象去自定义ClientHttpRequestFactory和the AsyncClientHttpRequestFactory。记住用兼容的方式跟踪实现(例如不要忘记在TraceAsyncListenableTaskExecutor封装ThreadPoolTaskScheduler )。请求工厂的示例:
@EnableAutoConfiguration
@Configuration
public static class TestConfiguration {
@Bean
ClientHttpRequestFactory mySyncClientFactory() {
return new MySyncClientHttpRequestFactory();
}
@Bean
AsyncClientHttpRequestFactory myAsyncClientFactory() {
return new MyAsyncClientHttpRequestFactory();
}
}
要阻止异步Rest模板的特性,可以设置spring.sleuth.web.async.client.enabled为false。想要阻止默认创建TraceAsyncClientHttpRequestFactoryWrapper,可以设置spring.sleuth.web.async.client.factory.enabled为false。如果你根本不想创建AsyncRestClient,可以设置spring.sleuth.web.async.client.template.enabled为false。
Feign
默认情况下,spring cloud Sleuth通过TraceFeignClientAutoConfiguration提供了对Feign的集成。你可以通过设置spring.sleuth.feign.enabled为false完全禁用它。如果你这样设置,spring cloud Sleuth不会加载任何你自定义的Feign组件工具。所有的默认工具还在。
异步调用
@Async注解的方法
在Spring Cloud Sleuth中,我们通过添加异步相关的组件,以至于跟踪信息能在线程之间传递。可以通过设置spring.sleuth.async.enabled为false,阻止默认的行为。
我们可以通过@Async注解方法,自动创建新的span有以下的特点:
- span的名称会变成注解的方法名。
- span会有方法所在的类名的标签和方法名的标签。
@Scheduled 注解的方法
在Spring Cloud Sleuth中,我们通过添加异步相关的组件,以至于跟踪信息能在线程之间传递。可以通过设置spring.sleuth.scheduled.enabled为false,阻止默认的行为。
我们可以通过@Scheduled注解方法,自动创建新的span有以下的特点:
- span的名称会变成注解的方法名。
- span会有方法所在的类名的标签和方法名的标签。
如果你想忽略某些@Scheduled 注解的方法自动创建span的话,可以通过设置spring.sleuth.scheduled.skipPattern为一个正则表达式会匹配所有@Scheduled注解的方法名,阻止创建span。
Executor, ExecutorService and ScheduledExecutorService
我们提供LazyTraceExecutor, TraceableExecutorService和TraceableScheduledExecutorService服务。这些实现会在新的任务的提交,调用,计划触发时,创建新的span。
这里我们在用CompletableFuture时可以看到如何通过TraceableExecutorService 传递跟踪消息的:
CompletableFuture<Long> completableFuture = CompletableFuture.supplyAsync(() -> {
// perform some logic
return 1_000_000L;
}, new TraceableExecutorService(executorService,
// 'calculateTax' explicitly names the span - this param is optional
tracer, traceKeys, spanNamer, "calculateTax"));
消息
Spring Cloud Sleuth和spring Integration集成了。它为发布和订阅时间创建了span。要禁用sring Integration的工具,可以设置pring.sleuth.integration.enabledfalse。
Spring Cloud Sleuth 1.0.4以下的版本一直通过消息发送不合法的跟踪消息头。这些头消息的名称实际上和http(包含-)的类似。从1.0.4开始往后的版本,我们开始发送合法的和不合法的头消息,请更新到1.0.4以上版本,因为Spring Cloud Sleuth 1.1以后我们不支持这些废弃的头消息了。
自从1.0.4版本我们可以提供spring.sleuth.integration.patterns表达式严格的提供你想要跟踪的名字频道。默认的情况下所有的频道都包含了。
Zuul
我们正在注册Zuul的过滤器去汇报跟踪信息(请求头信息中添加了跟踪信息)。可以设置spring.sleuth.zuul.enabled为false,禁用Zuul的支持。
运行中的例子
可以在Pivotal Web Services找到部署的运行中的例子。可以在以下链接检出: