$3
Spring cloud整合Netflix组件
spring-cloud在spring boot基础上,通过自动化配置,提供对netfix系统各组件的整合;并绑定到spring运行环境及各模块中。在您的分布式应用系统中,可以很方便的使用注解,去启用配置netflix这些强大的组件,实现分布式通用模式。例如 服务发现模式(Eureka),终端器模式(Hystrix),快捷路由模式(Zuul),客户端负载均衡模式(Ribbon)等。
服务发现: Eureka终端
服务发现模式是微服务化架构的关键原则。需要调用各服务的客户端的配置,或者让各模块都遵从一定形式的约定,很困难,也很繁琐。Eureka为netflix,服务端提供了注册服务,客户端提供发现服务。Eureka可以配置部署为高可用的服务,并暴露服务的状态会给其他注册的服务。
用Eurek注册服务
用Eureka注册服务,可以提供服务本身的基础数据,包括主机和端口,运行健康状态的诊断地址,主页等。Eureka负责接受注册服务所有实例的心跳信息。如果心跳超过配置的超时时间,该实例会被注册中心移除。
Eureka服务注册示例:
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
示例中,用@EnableEurekaClient注解严格的申明了注册Eureka服务;也可以使用@EnableDiscoveryClient开启Eureka,并使用application.yml配置Eureka服务:
application.yml
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
defaultZone是指如果注册客户端不提供服务注册中心url的默认返回地址。
运行环境中获取应用名称 (service ID),虚拟主机和非安全端口,分别是${spring.application.name}, ${spring.application.name}和 ${server.port}。@EnableEurekaClient,既在Eureka注册了一个服务本身实例,也声明了它是Eureka的客户端(可以查询到其他注册过的服务实例)。服务实例的所有的行为通过eureka.instance.*去配置,默认的行为已经足够了,当你确定的你的应用已经有spring.application.name(spring应用名是Eureka服务的标识)。
通过EurekaInstanceConfigBean 和 EurekaClientConfigBean 可以了解更多的详细配置。
通过Eurek服务认证
使用http协议的认证的方式会通过curl的方式自动将认证信息添加到url中,例如:http://user:password@localhost:8761/eureka 。如果有更多的需求,可以用@bean定义一个DiscoveryClientOptionalArgs,并且注入ClientFilter实例。
由于Eureka的限制,不支持单个服务的认证信息,因此只有第一个设置成功被发现的服务才会被采用。
状态页面和健康诊断
Eureka实例的状态页面和健康诊断的路径分别是/info和/health,也是spring boot实际应用的默认设置。在实际项目中需要修改服务器环境的管理地址,例如server.servletPath=/foo,management.contextPath=/admin
application.yml
eureka:
instance:
statusPageUrlPath: ${management.context-path}/info
healthCheckUrlPath: ${management.context-path}/health
这些链接能够提供服务本身的基本信息,以判断客户端是否向该应用请求服务。确保这些信息的准确性,会很有帮助。
注册安全的应用
如果你的应用希望用https安全协议的话,你可以通过设置EurekaInstanceConfig的两个标志位实现:eureka.instance.nonSecurePortEnabled=false,eureka.instanceeureka.instance.securePortEnabled=true
这会让Eureka发布实例的时候,显示必须通过严格使用安全连接的方式连接服务。这样,服务发现终端会一直返回https://…开头的服务路径。url这样配置的服务,Eureka会对服务作安全连接的检查。
由于Eureka内部的实现方式,仍然会有非安全连接的状态地址和主页对外发布,除非你还严格的重写这一部分配置。例如:
application.yml
eureka:
instance:
statusPageUrl: https://${eureka.hostname}/info
healthCheckUrl: https://${eureka.hostname}/health
homePageUrl: https://${eureka.hostname}/
注意:${eureka.hostname} 替换表达式仅对Eureka后期的版本有效。你还可以使用${eureka.instance.hostName}同样的替换。
如果你的应用通过理服务器代理运行,ssl的终端也在代理服务器上(例如,使用Cloud Foundry或者其他的平台上发布服务),需要确保代理服务器把所有请求推送的头消息已经被解析成你的应用能处理的消息内容。如果请求包含
X-Forwarded-\*头消息,spring boot内置的tomcat服务器会自动处理。你的应用可能会误发包含the wrong host, port or protocol错误提示的链接。
Eureka的健康检查
默认情况下 ,Eureka会利用客户端的心跳信息判断客户端是否在线。除非服务发现终端不能上报spring boot实际应用生成的当前健康诊断结果。这表示服务一注册成功,Eureka就会通知发现终端服务是在线的状态。该行为可以通过健康诊断设置调整,重新定义应用健康状态的上报方式。因此,非在线状态的应用也不会上报具体的状态信息。
application.yml
eureka:
client:
healthcheck:
enabled: true
如果你需要控制健康检查,可以自己考虑重新实现com.netflix.appinfo.HealthCheckHandler。
Eureka实例和客户端的基本信息
花点时间去理解Eureka各基本组成信息的工作原理是值得的,将会在你的平台里面把Eureka使用的更有意义。主机名,ip地址,端口号,状态页面和安全检查是标准的组成部分。服务注册成功后,会发布这些连接信息给客户端,之后客户端可以这些信息直接找到并连接服务。其他的信息在实例注册时会被添加到eureka.instance.metadataMap,这些信息对于远程的客户端可见,但是,通常情况下这些不会影响客户端的行为,除非让客户端知道我们对于这些信息赋予了一些含义。后文中将会指出spring cloud已经对某些信息赋予的意义。
在Cloudfoundry上使用Eureka
Cloudfoundry有一个服务所有的实例都使用同一主机名的全局路由(这也是一个类似平台即软件的类似架构)。这不会影响你使用Eureka,但如果你使用路由(推荐使用路由,可能根据你的设置可能是必需的方式),你必须严格的指定主机名和端口(安全的或非安全的)让这些实例使用路由。如果你希望实例服务附带其他的信息,以便于区别这些实例(如做负载均衡)。默认情况下eureka.instance.instanceId 是 vcap.application.instance_id 。
application.yml
eureka:
instance:
hostname: ${vcap.application.uris[0]}
nonSecurePort: 80
取决于你在Cloudfoundry上设置的安全规则,你可能会去使用ip地址和端口去对服务进行直接调用,Pivotal Web Services 目前还未支持这一特性。
在aws上使用Eureka
如果Eureka打算用到aws云服务器上,那么Eureka需要打包成amazon组件,可以用EurekaInstanceConfigBean 配置:
@Bean
@Profile("!default")
public EurekaInstanceConfigBean eurekaInstanceConfig() {
EurekaInstanceConfigBean b = new EurekaInstanceConfigBean();
AmazonInfo info = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
b.setDataCenterInfo(info);
return b;
}
修改Eureka id
普通的Eureka通过id注册实例,相当于它的主机名(一个主机一个服务)。Spring Cloud Eureka提供了更有意义的默认格式:
${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance_id:${server.port}}}。
例如myhost:myappname:8080。
Spring Cloud允许用eureka.instance.instanceId重新指定你自己的唯一id。
application.yml
eureka:
instance:
instanceId: ${spring.application.name}:${spring.application.instance_id:${random.value}}
通过这一设置,可以注册同一个服务的多个实例,以随机数作为id,并保证实例的唯一。在Cloudfoundry中spring.application.instance_id会自动生成,所以随机数没有必要。
使用Eureka客户端
一旦你使用@EnableDiscoveryClient(或者@EnableEurekaClient) ,就可以通过Eureka服务发现服务了。也可以用原生的com.netflix.discovery.EurekaClient(而不用spring cloud的DiscoveryClient),例如:
@Autowired
private EurekaClient discoveryClient;
public String serviceUrl() {
InstanceInfo instance = discoveryClient.getNextServerFromEureka("STORES", false);
return instance.getHomePageUrl();
}
不要在@PostConstruct方法中或者@Scheduled方法或者其他应用上下文或许未开始的地方使用EurekaClient.它在最初阶段(phase=0)初始化,因此往后的阶段里面可以使用。
原生EurekaClient的替代方案
你不必使用原生的EurekaClient,通常经过一系列的封装后会更好使用。Spring Cloud提供了 Feign(REST客户端的构建框架),spring还提供了rest template用逻辑服务id取代实际的物理url地址的方案。设置<client>.ribbon.listOfServers可以用Ribbon代理,分割的服务地址列表,这里的<client>表示终端的id。
你还可以用org.springframework.cloud.client.discovery.DiscoveryClient提供netflix没有特别强调的简单的服务发现api。
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
为何注册一个服务这么慢?
默认每隔30秒,服务实例需要通过客户端的serviceUrl发出心跳信息到注册中心。实例、服务、客户端都已经缓存了共同的基础信息后(需要3次心跳的时间)。你可以改变leaseRenewalIntervalInSeconds 参数加速客户端连接到服务的过程。但是,生产环境中,建议使用默认值,这是许多计算,得出来适合连接到服务释放连接的周期值。
服务发现: Eureka服务端
Eureka服务端示例(用spring-cloud-starter-eureka-server设置classpath)
@SpringBootApplication
@EnableEurekaServer
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
Eureka服务端有一个带界面的主页,以及http的api服务节点在/eureka/*路径下
Eureka参考资料:可见 flux capacitor 和 google group discussion。
按照Gradle的依赖解决方案以及缺少父bom的特性,简单的依赖spring-cloud-starter-eureka-server会导致应用启动失败。为了解决这一问题,必须加上spring gradle plugin插件,并且spring cloud 父bom应该像这样必须被引用:
build.gradle
buildscript {
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:1.3.5.RELEASE")
}
}
apply plugin: "spring-boot"
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
高可用,时区,区域
Eureka的服务端并没有后端存储,但是注册过的每个服务实例有必须持续发送心跳信息以保持注册状态(因此这部分可以在内存中实现)。客户端也有自己的内存缓存(因此不必每次都得向注册中心获取服务并请求)。
每一个Eureka服务端也是一个客户端,因此至少需要一个服务的serice url地址,找到其它的节点。如果你不提供这个url,服务端会运行并且工作,但是它会提出一大堆的日志文件,报无法和其他的一端去注册服务。
以下可以了解更多Ribbon支持的客户端时区以及区域详细信息。
标准模式
客户端和服务的缓存结合方式以及心跳会使Eureka平滑的停止,只要一些监控器或者弹性时间让他保持活跃,例如(Cloud Foundry).在标准模式下,你可能想要关掉所有客户端的行为,让客户端不再继续尝试连接其他的端但一直失败。
application.yml
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
注意serviceUrl是指向本地实例相同的主机名。
端通知
Eureka可以被设置为更加有弹性,启动多个实例,也可以相互之间注册。实际上,这是默认的行为,所以,只要添加一个正确的serviceUrl就可以给任一一个节点注册运行。
application.yml
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
client:
serviceUrl:
defaultZone: http://peer2/eureka/
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
client:
serviceUrl:
defaultZone: http://peer1/eureka/
以上实例中,我们在同一个服务器上用yml指定了2个主机peer1,peer2;运行在不同的spring对象里。你可以用这个在同一个服务器上测试节点的发现(实际生产环境上很少这样做的),通过管理/etc/hosts文件解决主机名的问题。实际上,主机名eureka.instance.hostname也不必制定,如果你运行在一个知道自己主机名的机器上(默认情况下通过java.net.InetAddress查找主机名)。
你可以添加多个节点到系统中去,只要它们相互之间能够直连,它们将会同步相互之间的注册。
application.yml (Three Peer Aware Eureka Servers)
---
eureka:
client:
serviceUrl:
defaultZone: http://peer1/eureka/,http://peer2/eureka/,http://peer3/eureka/
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
---
spring:
profiles: peer3
eureka:
instance:
hostname: peer3
推荐ip地址
在某些情况下,用Eureka推荐使用ip地址而不是主机名,把eureka.instance.preferIpAddress设为true时,每个节点相互注册发现服务的时候会用ip地址而不会用主机名。
断路器:Hystrix客户端
Netflix有一个Hystrix库实现了断路器模式,在微服务的架构中,服务之间多层调用是很常见的。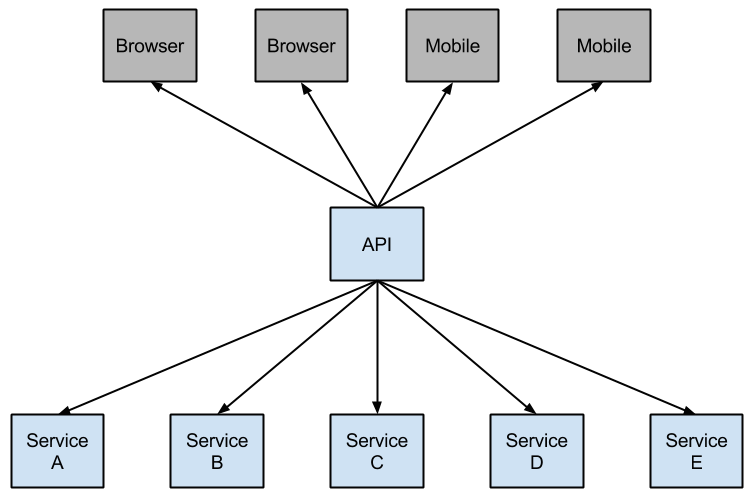
1. Microservice Graph
一个底层的服务出现问题的时候,会对上层的各级服务造成级联影响。当对某个服务的调用达到了一定数据的失败(Hystrix中默认5秒内20次失败),请求链路就会断开,该请求也不会生成。以防发生错误或者请求断路,开发人员应提供回馈。
2. Hystrix 回馈,防止级联失败
发生断路后阻止多层的级联请求失败,并且为出错的服务留有一定的时间去修复。回馈可能会是Hystrix保护的服务调用,静态数据,或者是毫无意义的空数据。回馈响应的也可能是Hystrix链上的其他的业务回调,返回静态数据。
boot应用实例:
@SpringBootApplication
@EnableCircuitBreaker
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
@Component
public class StoreIntegration {
@HystrixCommand(fallbackMethod = "defaultStores")
public Object getStores(Map<String, Object> parameters) {
//do stuff that might fail
}
public Object defaultStores(Map<String, Object> parameters) {
return /* something useful */;
}
}
@HystrixCommand是一个叫"javanica"的Netflix contrib库。Spring Cloud 通过这个注解自动封装把Spring对象连接到Hystrix断路器上。Hystrix负责什么时候断开,什么时候闭合,以及出错的时候该如何响应。
你可以用一系列@HystrixProperty注解去配置@HystrixCommand的属性。这里我们可以查看更多详细。Hystrix wiki有更多的详细属性介绍。
提升到安全边界或者spring范围
如果你想某些线程内部上下文受@HystrixProperty控制是无效的,因为它会在线程池里面执行命令(几次超时后)。你可以把Hystrix的调用线程和配置放到一个线程中,或者直接显示的用注解申明,让它用另一个隔离策略。例如:
@HystrixCommand(fallbackMethod = "stubMyService",
commandProperties = {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")
}
)
...
用@SessionScope 或者 @RequestScope是一样的效果。由于找不到范围内的上下文运行异常发生,你才会知道要这样设置。
安全诊断
接入的断路器的状态信息会暴露在调用了该断路器的应用的/health路径下。
"hystrix": {
"openCircuitBreakers": [
"StoreIntegration::getStoresByLocationLink"
],
"status": "CIRCUIT_OPEN"
},
"status": "UP"
}
Hystrix度量流
开启Hystrix度量流,需要引入spring-boot-starter-actuator依赖。这会把/he暴露为管理路径。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
断路器:Hystrix面板
Hystrix一个最大的好处是可以设置收集HystrixCommand信息的度量。Hystrix面板有效的展示出每个断路器的
健康状态。
3. Hystrix Dashboard
启用Hystrix面板需要在你的spring boot应用主函数上添加注解@EnableHystrixDashboard。然后就可以访问/hystrix路径,把/hystrix.stream指向Hystrix客户端应用了。
Turbine
查看一个Hystrix单个实例的所有的安全数据没有太大的意义。Turbine是一个统一集合一个个相关的Hystrix /hystrix.stream端到/turbine.stream,并应用到Hystrix面板上。单个实例都部署在Eureka下。应用Turbine简单到只要在你的spring boot应用主函数上添加注解@EnableTurbine。应用了the Turbine 1 wiki)的所有的配置的属性。唯一的区别就是turbine.instanceUrlSuffix不必添加端口,这是因为系统已经自动处理了,除非你设置turbine.instanceInsertPort=false。
turbine.appConfig配置是一系列eureka服务id,turbine用来查找其他实例用的。因此turbine流在Hystrix面板上使用的地址看起来像http://my.turbine.sever:8080/turbine.stream?cluster=<CLUSTERNAME>类似如果 (cluster参数可以去掉,如果你的CLUSTERNAME是"default"的话)。CLUSTERNAME一定要匹配turbine.aggregator.clusterConfig的其中一个。
eureka会返回大写的结果,如果有某个应用在Eureka中注册的名字是"customers"的话:
turbine:
aggregator:
clusterConfig: CUSTOMERS
appConfig: customers
CLUSTERNAME还可以通过InstanceInfo生成的实例为基础用spel表达式去指定。默认值是应用名,意味着Eureka 服务id以集群键结束(customers的实例信息以"CUSTOMERS"为应用名)。不一样的情况有turbine.clusterNameExpression=aSGName会以aws asg名称。另一个例子是:
turbine:
aggregator:
clusterConfig: SYSTEM,USER
appConfig: customers,stores,ui,admin
clusterNameExpression: metadata['cluster']
这样的情况下,这4个服务的集群名是从基础元素图里生成,并且期望值会包含"SYSTEM"和"USER"。
想要用"default"作为所有应用的集群,需要用字符串(需要用单引号'',在YAML文件中需要双引号""转义)。
turbine:
appConfig: customers,stores
clusterNameExpression: "'default'"
Spring Cloud提供spring-cloud-starter-turbine库,包含了所有运行Turbine服务所需要的依赖。只需要创建一个spring boot应用,并且加上注解@EnableTurbine。
Netflix包含的Turbine行为默认不能在同一集群同一个主机上运行多个进程(主机名是实例id的键)。如果你设置了
turbine.combineHostPort=true属性,Spring Cloud允许使用主机名和端口作为键生成。
Turbine流
在某些环境下(例如:paas设置中),传统Turbine模式,无法从分布式系统中获取度量数据是无法正常运行的。这种情况下,你或许需要把Hystrix命令把度量信息推送到Turbine中,并且Spring Cloud允许使用消息开启这一功能。如果你愿意的话,你只需要把spring-cloud-netflix-hystrix-stream和the spring-cloud-starter-stream-*加入到你的客户端依赖中(看 Spring Cloud Stream说明文档了解消息调用者,如何配置客户端的认证信息,但应该本地调用也应该可行)。
在服务端只需要创建spring boot应用并且添加@EnableTurbineStream注解,默认情况下会从8989端口启动(把你的Hystrix面板的所有路径指向这个端口)。
你可以通过server.port或turbine.stream.port自定义自己的端口。如果你的项目classpath下包含spring-boot-starter-web和spring-boot-starter-actuator,你还可以通过management.port指定另外一个管理端口。
你可以把Hystrix 面板指向Turbine流的路径,而不是单个Hystrix流。如果在我主机上Turbine流运行在8989端口上,在Hystrix面板上流字段中则输入http://myhost:8989。断路器以服务id开始,加上.,加上断路器的名字。
spring cloud提供了spring-cloud-starter-turbine-stream库,包含了所有需要获取Turbine流服务需要的所有依赖,只需要添加你的流绑定,如果你愿意,可以选择spring-cloud-starter-stream-rabbit。因为是基于netty,你需要java8运行应用。
客户端的负载均衡:Ribbon
Ribbon客户端负载均衡通过http和tcp客户端提供了很多的控制。Feign也使用了Ribbon,因此只需要使用@FeignClient,也会包含这一部分的功能。
Ribbon核心的概念是命名了的客户端。 每一个负载客户端都是配合服务器命令有机合作整体的一部分,而这个整体需要开发人员给他命一个名字(例如用@FeignClient命名)。Sping cloud用RibbonClientConfiguration建立了应用上下文作为一个整体满足任意一个命名的客户端需要。这包含一个ILoadBalancer, 一个RestClient,和一个ServerListFilter.
自定义Ribbon客户端
你可以用一些额外的<client>.ribbon.*属性配置Ribbon客户端,和原生的Netflix API没有任何区别,除非你用Spring Boot的配置文件。在CommonClientConfigKey中(Ribbon的一部分核心)本身的一些选项可以被认为是静态属性。
Spring cloud还允许你通过一些额外的配置(在RibbonClientConfiguration上面)使用@RibbonClient完全控制Ribbon客户端。例如:
@Configuration
@RibbonClient(name = "foo", configuration = FooConfiguration.class)
public class TestConfiguration {
}
这种情况下,客户端已经包含了了RibbonClientConfiguration 和FooConfiguration 所配置各组件(一般的,后者会覆盖前者的配置)。
FooConfiguration必须要通过@Configuration配置,但要注意,并不是在主应用环境中@ComponentScan被扫描,否则的话,它会被所有的@RibbonClients共享。如果你在应用中使用@ComponentScan (或者 @SpringBootApplication)你需要防止被包含到(例如,可以把它放到一个单独的不会重叠的包里,或者用@ComponentScan指定要扫描的包)。
spring Cloud Netflix默认在ribbon添加了以下对象(对象类型 对象名称 : 类名):
- IClientConfig ribbonClientConfig: DefaultClientConfigImpl
- IRule ribbonRule: ZoneAvoidanceRule
- IPing ribbonPing: NoOpPing
- ServerList
ribbonServerList: ConfigurationBasedServerList - ServerListFilter
ribbonServerListFilter: ZonePreferenceServerListFilter - ILoadBalancer ribbonLoadBalancer: ZoneAwareLoadBalancer
创建一个以上这些类型的对象(和上例中的FooConfiguration一样),替换到@RibbonClient注解中,可以重写任意一个对象。
@Configuration
public class FooConfiguration {
@Bean
public IPing ribbonPing(IClientConfig config) {
return new PingUrl();
}
}
@Configuration
public class FooConfiguration {
@Bean
public IPing ribbonPing(IClientConfig config) {
return new PingUrl();
}
}
在这里用PingUrl替换了默认值NoOpPing(不ping服务实例)。
结合Eureka使用Ribbon
当Eureka和Ribbon混合使用的时候,ribbonServerList被继承自DiscoveryEnabledNIWSServerList的类重写了,通过Eureka发布这些服务。IPing接口也被NIWSDiscoveryPing取代了,可以代表Eureka决定服务是否上线。默认的服务列表是DomainExtractingServerList,这样的目的是使物理的基础信息对于负载均衡是可用的,而不需要AWS AMI基础信息(Netflix所依赖的基础信息)。默认情况下,服务列表信息会被存储在实例所应该提供的基础信息zone中(远程客户端需要设置eureka.instance.metadataMap.zone),如果缺失的话,可以用主机名作为zone的代理(只要approximateZoneFromHostname 参数已经设置了)。zone信息一设置好就可以在ServerListFilter服务列表过滤器中去使用。默认情况下该信息会被用来定位服务器,客户端也是,默认用ZonePreferenceServerListFilter区域首选服务列表过滤器。客户端和远程实例一样,默认通过eureka.instance.metadataMap.zone来决定。
常用的"archaius"方式是通过@zone属性设置客户端的范围的。spring cloud也会采用这个设置,优先于其他可用的设置(注意yaml配置文件用中要用引号引用)。 如果没有其他的区域数据源,将会根据客户端的配置去推测一个(和实例的配置相反)。我们用eureka.client.availabilityZones,这是一个区域名导一系列区域的映射图,并且把实例自己的区域名排出来。(例如,原生的Netflix中eureka.client.region默认是"us-east-1")。
示例:如何不结合Eureka使用Ribbon
Eureka是一种很方便的整合发现远程服务的方式,不需要在客户端把地址硬编码到项目中,如果你选择不使用它,Ribbon和 Feign也是很好的搭配。假设,你用@RibbonClient定义了一些"stores",没有使用Eureka(连classpath下也没有),可以像这样配置Ribbon的客户端:
application.yml
stores:
ribbon:
listOfServers: example.com,google.com
在Ribbon禁用Eureka
设置ribbon.eureka.enabled = false属性可以严禁Eureka。
application.yml
ribbon:
eureka:
enabled: false
直接使用Ribbon的api接口
还可以直接使用LoadBalancerClient。例如:
public class MyClass {
@Autowired
private LoadBalancerClient loadBalancer;
public void doStuff() {
ServiceInstance instance = loadBalancer.choose("stores");
URI storesUri = URI.create(String.format("http://%s:%s", instance.getHost(), instance.getPort()));
// ... do something with the URI
}
}
申明rest客户端:Feign
Feign是用来申明web service客户端的。用它写web service客户端很容易。用feign创建一个接口,并添加注解。插件式的支持feign注解和JAX-RS注解。Feign还支持插件式的加密和解密部分。Spring Cloud添加了对spring mvc的支持,默认通过HttpMessageConverters可以添加到web服务中。Spring Cloud继承了Ribbon和Eureka可以用feign提供对http客户端的负载均衡。
spring boot应用示例:
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@EnableFeignClients
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
StoreClient.java
@FeignClient("stores")
public interface StoreClient {
@RequestMapping(method = RequestMethod.GET, value = "/stores")
List<Store> getStores();
@RequestMapping(method = RequestMethod.POST, value = "/stores/{storeId}", consumes = "application/json")
Store update(@PathVariable("storeId") Long storeId, Store store);
}
在这个示例中@FeignClient的名称“stores”是一个确切客户端的名称,用来创建Ribbon客户端负载均衡查看关于ribbon支持的详细说明。你也可以指定一个url(完成的url或者主机名)。还要在应用上下文中为这个对象建立一个合格的名称。除了FeignClient还有一个name属性用来取别名的。如上实例:@Qualifier("storesFeignClient")是用来指向这个对象的。
以上ribbon客户端希望定位到“stores”服务的实际物理地址。如果你用了Eureka,它会向Eureka服务注册中心找地址。如果你不想用Eureka,你可以在配置文件中添加一些服务的配置。查看这个示例。
修改Feign默认设置
为客户端命名是Spring Cloud中对Feign支持的一个核心概念。每一个负载客户端都是配合服务器命令有机合作整体的一部分,而这个整体需要开发人员给他命一个名字(例如用@FeignClient命名)。Sping cloud用FeignClientsConfiguration建立了应用上下文作为一个整体满足任意一个命名的客户端需要。这包含一个feign.Decoder,一个feign.Encoder和一个feign.Contract。
Spring cloud还允许你通过一些额外的配置(在RibbonClientConfiguration上面)使用@RibbonClient完全控制feign 客户端。例如:
@FeignClient(name = "stores", configuration = FooConfiguration.class)
public interface StoreClient {
//..
}
这种情况下,客户端已经包含了了FeignClientsConfiguration 和FooConfiguration 所配置各组件(一般的,后者会覆盖前者的配置)。
FooConfiguration必须要通过@Configuration配置,但要注意,并不是在主应用环境中@ComponentScan被扫描,否则的话,它会被所有的@FeignClient共享。如果你在应用中使用@ComponentScan (或者 @SpringBootApplication)你需要防止被包含到(例如,可以把它放到一个单独的不会重叠的包里,或者用@ComponentScan指定要扫描的包)。
注意:serviceId已经被废弃了,使用name属性取代了。
name和url属性可以用spring el表达式替换。
@FeignClient(name = "${feign.name}", url = "${feign.url}")
public interface StoreClient {
//..
}
Spring Cloud Netflix为feign提供了以下对象(对象类型 对象名:类名)。
Decoder feignDecoder: ResponseEntityDecoder (which wraps a SpringDecoder)
Encoder feignEncoder: SpringEncoder
Logger feignLogger: Slf4jLogger
Contract feignContract: SpringMvcContract
Feign.Builder feignBuilder: HystrixFeign.Builder
Spring Cloud Netflix不提供了以下对象,但是会从应用上下文中去找这些类型的对象。
Logger.Level
Retryer
ErrorDecoder
Request.Options
Collection
创建一个以上这些类型的对象(和上例中的FooConfiguration一样),替换到@FeignClient,可以重写任意一个对象。
@Configuration
public class FooConfiguration {
@Bean
public Contract feignContract() {
return new feign.Contract.Default();
}
@Bean
public BasicAuthRequestInterceptor basicAuthRequestInterceptor() {
return new BasicAuthRequestInterceptor("user", "password");
}
}
这会用feign.Contract.Default替换SpringMvcContract,并会添加一个请求过滤器到过滤器集合中。
在@EnableFeignClients中defaultConfiguration属性可以添加和以上一样添加默认属性,区别是这个配置会对所有的feign的客户端生效。
Feign Hystrix支持
如果Hystrix在classpath下,Feign会为每一个方法封装断路器。还可以返回com.netflix.hystrix.HystrixCommand。这允许你进行响应式编程模式(调用.toObservable()或者.observe()或异步使用.queue()方法调用)。
禁用Hystrix对Feign的支持,设置feign.hystrix.enabled=false。
对单个禁用Hystrix的基础客户端,可以在 "prototype"范围内创建一个Feign.Builder。例如:
@Configuration
public class FooConfiguration {
@Bean
@Scope("prototype")
public Feign.Builder feignBuilder() {
return Feign.builder();
}
}
Feign Hystrix回馈
Feign Hystrix支持这种回馈,当断路器断开或者发生错误的时候,运行指定的某段代码块。
对于一个给定的@FeignClient启用这样的回馈,需要设置fallback属性为一个对HystrixClient的实现的类名。
@FeignClient(name = "hello", fallback = HystrixClientFallback.class)
protected interface HystrixClient {
@RequestMapping(method = RequestMethod.GET, value = "/hello")
Hello iFailSometimes();
}
static class HystrixClientFallback implements HystrixClient {
@Override
public Hello iFailSometimes() {
return new Hello("fallback");
}
}
对HystrixClient的回馈以及如何实现有这样的一个限制:不能返回com.netflix.hystrix.HystrixCommand的rx.Observable。
Feign继承的实现
Feign支持普通对这个单继承接口的的实现。它允许一些公共的通用接口的分组操作。
UserService.java
public interface UserService {
@RequestMapping(method = RequestMethod.GET, value ="/users/{id}")
User getUser(@PathVariable("id") long id);
}
UserResource.java
@RestController
public class UserResource implements UserService {
}
UserClient.java
package project.user;
@FeignClient("users")
public interface UserClient extends UserService {
}
注意:通常情况下,不建议客户端和服务端公用一个接口,这加深了耦合,也不符合的spring mvc的工作方式(方法的参数映射没有映射)。
Feign压缩文件的请求响应
你或许需要开启Feign的请求响应压缩功能。你可以用以下一个属性去实现:
feign.compression.request.enabled=true
feign.compression.response.enabled=true
Feign对请求的压缩提供了和web服务类似的设置:
feign.compression.request.enabled=true
feign.compression.request.mime-types=text/xml,application/xml,application/json
feign.compression.request.min-request-size=2048
这些属性提供了对关于请求中的压缩文件流类型和最小尺寸范围限制。
Feign日志
每个Feign客户端都会创建日志文件。日志的文件名默认是创建Feign客户端创建的类名。Feign日志的响应级别是debug。
application.yml
logging.level.project.user.UserClient: DEBUG
你可以为单个客户端设置Logger.Level,告诉Feign日志的尺寸大小,选项有:
NONE, No logging (DEFAULT).
BASIC, Log only the request method and URL and the response status code and execution time.
HEADERS, Log the basic information along with request and response headers.
FULL, Log the headers, body, and metadata for both requests and responses.
如下,可以设置全文日志:
@Configuration
public class FooConfiguration {
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}
更多的配置:Archaius
Archaius是Netflix客户端配置的库。所有Netflix开源库组件都用这个库做配置。它来源于Apache Commons Configuration项目。它既允许从源配置中获取配置的改变,也允许客户端向源配置中推出一些更新。Archaius用动态类型属性类去处理配置。
Archaius Example
class ArchaiusTest {
DynamicStringProperty myprop = DynamicPropertyFactory
.getInstance()
.getStringProperty("my.prop");
void doSomething() {
OtherClass.someMethod(myprop.get());
}
}
Archaius有它自己的一群配置文件和加载优先级。Spring应用应该不必广泛的使用Archaius,一定要用到netflix工具的时候仍然需要。Spring Cloud的Spring系统环境提供了Archaius直接从系统环境中读取属性。Spring Boot项目提供了很多的系统环境的配置方式,大部分文档中记录的,都可以应用到netflix工具中。
路由和过滤:Zuul
路由在微服务架构的整体中的部分。例如:/可能是应用的根路径,/api/users映射到用户服务,/api/shop映射到电商服务。Zuul是基于jvm的路由,也是netflix应用的服务端负载均衡。
netflix用了Zuul这些:
认证
监控分析
压力测试
金丝雀测试
动态路由
服务迁移
负载分级Load Shedding
安全
静态响应处理
数据流/数据流管理Active/Active traffic management
Zuul的规则引擎的规则和过滤用基础的jvm语言可以写,但部署需要java和groove。
zuul.max.host.connections的配置属性已经被zuul.host.maxTotalConnections和zuul.host.maxPerRouteConnections 所取代,默认值分别是200和20。
内置的Zuul反向代理
当一个有交互界面的应用需要调用一个或多个服务端的时候,Spring Cloud已经提供了创建内置的方向代理方便部署的方法。这一特性对前端接口需要代理到后端服务很有用,不需要考虑后端的跨域请求或者身份认证等问题。
在spring boot应用主函数上使用@EnableZuulProxy注解,可以开启,这会把所有本地的请求推送到对应的服务端去。遵从约定,对user服务的请求一般会被代理到/users路径(在服务名前面加上/)。代理使用robbin定位服务并查找注册服务,所有都请求都以hystrix命令执行;请求失败会在Hystrix metrics中显示,一旦断路器断开,代理就不用连接到服务端。
Zull启动不会包含服务发现客户端,因此基于服务id的路由需要你提供一个类库放到classpath下(例如Eureka是一个不错的选择)。
以防服务自动添加,可以把zuul.ignored-services设置为一系列服务模式。如果一个服务在满足忽略的服务模式,但有严格的显示申明了在配置的路由映射里面,它仍然会被忽略。
application.yml
zuul:
ignoredServices: '*'
routes:
users: /myusers/**
这个例子中除了users所有的路径都被忽略了。 参数化配置路由股则,可以如下这样添加配置:
application.yml
zuul:
routes:
users: /myusers/**
这表示对/myusers的请求会被转到users服务中,(例如"/myusers/101" 会被推送到"/101")。 想要更好的控制,你可以单独的对路径和服务分别进行指定。
application.yml
zuul:
routes:
users:
path: /myusers/**
serviceId: users_service
这意味着这表示对/myusers的请求会被转到users_service服务。路由的路径是蚂蚁模式设置的,例如 /myusers/只会匹配一层, /myusers/*会匹配这个垂直结构。 后端服务可以被定位为一个服务id(服务发现),也可以是一个url地址(物理地址)。
这些简单的url路由没有用HystrixCommand执行,也没通过ribbon对多个url进行负载均衡。要做到这样,需要指定服务路由并且为服务id配置一个ribbon的客户端(这部分目前需要关掉Eureka对ribbon的支持),查看详细信息。
application.yml
zuul:
routes:
users:
path: /myusers/**
serviceId: users
ribbon:
eureka:
enabled: false
users:
ribbon:
listOfServers: example.com,google.com
还可以用服务和路由通过正则表达式匹配规则去约定。这会从名称组对服务变量匹配处理,并注入到吗某个路由的模式中。
ApplicationConfiguration.java
@Bean
public PatternServiceRouteMapper serviceRouteMapper() {
return new PatternServiceRouteMapper(
"(?<name>^.+)-(?<version>v.+$)",
"${version}/${name}");
}
这表示"myusers-v1"会被映射到"/v1/myusers/**"路由中。任意的正则表达式都可以被接受,但是所有的名称组都要在服务模式和路由模式中出现。如果服务模式没有匹配上服务id,则会执行默认行为。以上实例中myusers服务会匹配映射到/myusers/**路由 (未发现任何版本的话) ,这一特性会无效,只会应用到发现的服务。
对zuul.prefix设置一个值(例如/api)会对所有映射添加一个前缀。默认情况下,代理会在请求发送到推送之前添加前缀(设置zuul.stripPrefix=false可以修改这一默认行为),你也可以对单个的路由进行禁用前缀。例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
stripPrefix: false
这表示对/myusers/101" 会被推送到"myusers/101"请求users服务。
zuul.routes分支会被绑定到ZuulProperties类型的对象中去。如果你查看了属性列表,你会发现还有一个retryable标识属性。把这个属性设为true的话,ribbon在请求失败后会自动重新尝试失败的请求(如果你需要,当然你还可以对ribbon的配置修改尝试请求的参数)。
X-Forwarded-Host头信息会默认添加到推送的请求头中,通过zuul.addProxyHeaders = false可以关闭。请求路径默认添加前缀是从服务端请求头的X-Forwarded-Prefix获取的(以上实例中是/myusers)。
如果你设置了/作为默认路由,@EnableZuulProxy注解的应用可以作为一个标注的服务。zuul.route.home: / 会把所有的网络请求(例如"/**") 指向"home"服务。
如果需要指定忽略的请求,可以指定需要忽略的正则表达式。这些表达式会在路由路径的开始就计算,这意味着前缀也要考虑到。忽略的模式会无视所有的服务,并且超越所有其他的路由配置。
application.yml
zuul:
ignoredPatterns: /**/admin/**
routes:
users: /myusers/**
这表示对/myusers/101" 会被推送到"myusers/101"请求users服务。但是包含/admin/的路径不会被处理。
缓存和敏感的头部信息
在同一个系统中的多个服务之间共享头消息没有什么问题,但你不太可能希望把敏感的一些头部信息泄露到外部服务上。你可以通过路由设置忽略一部分的头消息。缓存扮演了很特殊的角色,并在浏览器设置中的定义好的部分,通常被作为敏感信息处理。如果访问你的代理的是浏览器,对于下游的服务看来说,这么多的cookie看起来完全一团糟,也会给用户会带来问题(下游的服务看上去,请求来自同一个地方)。
如果你对于自己的服务设计的很仔细的话,例如某个服务需要设置缓存,你会希望缓存从服务端一直到服务调用端被设置。同样,如果你的代理设置服务了,所有的后端服务就像整个系统,很自然的就会简单的共享这些缓存(例如可以用spring session把这些服务链接到某个共享的状态)。另外,所有下游服务需要设置的cookie对于用户本身是没有多少意义的,所以建议在头消息中不要设置自己领域需要的cookie。认真考虑,分某个服务私有范围的那部分缓存对于服务和代理之间代表着什么。 敏感的头信息,可以用,分割,例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders: Cookie,Set-Cookie,Authorization
url: https://downstream
敏感的头消息也可通过zuul.sensitiveHeaders全局设置,如果路由上设置了sensitiveHeaders,会覆盖其他全局的敏感头信息设置。
sensitiveHeaders有默认初始值,因此没有必要去修改,除非你希望这里作不一样的设置。 Spring Cloud Netflix 1.1才支持的,1.0用户对头消息和缓存怎么流是没有控制的。 对于单个路由的敏感头消息,还可以在zuul.ignoredHeaders中设置值,取消在请求和响应之间某些头信息的交互。默认情况下这里空值,除非你的classpath下添加了Spring Security,否则Spring Security指定了我们都知道的security头消息。总结这个情况,这里下游的服务可能需要这些头信息,我们也需要从代理中附带这些头消息。
如果你在spring boot Actuator 用@EnableZuulProxy配置的话会添加一个/routes路径可以通过http请求。对这个路径进行get请求会获取到一个映射的路由列表,一个post请求会强制这些路由列表的更新(以防服务目录会被更新)。
服务目录的变化会自动及时响应,但是post请求会强制让这些改变立即生效。
转移策略与本地推送
把在用的应用或者api的迁移的一种通用模式是迁移原来的路径。Zuul代理会很有用,因为你可以处理原路径下的所有请求,仅重定向一部分其中一部分请求到新的接口服务下。
示例配置:
application.yml
zuul:
routes:
first:
path: /first/**
url: http://first.example.com
second:
path: /second/**
url: forward:/second
third:
path: /third/**
url: forward:/3rd
legacy:
path: /**
url: http://legacy.example.com
这里我们把映射到所有请求的遗留应用,拆分到不满足匹配模式的。/first/**会被替换到一个新URL的新的服务,/second/*会被推送到本地添加了@RequestMapping spring注解的服务,/third/\*会被推送到添加了/3rd前缀的路径。
忽略的模式不会完全被忽视,他们不会被代理处理,(应此会很有效的推送到本地)。
通过zuul上传文件
用@EnableZuulProxy注解,你可以通过zuul代理上传文件,只要文件比较小,应该直接就可用。大的文件我们需要通过Spring DispatcherServlet中配置在/zuul/*的其他路径,例如zuul.routes.customers=/customers/**,就可以把大文件上传到/zuul/customers/**路径下。serletpath的路径通过zuul.servletPath另外定义的。如果代理路由通过ribbon负载均衡处理了,对于极大的文件需要上传,那么需要设置超时时间。例如:
application.yml
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000
注意,处理超大文件流,你需要在请求中使用chunked加密方式(默认情况下,许多浏览器中一般不会这么做)。例如:
$ curl -v -H "Transfer-Encoding: chunked" \
-F "file=@mylarge.iso" localhost:9999/zuul/simple/file
简单内置的Zuul
你可以不用代理单独运行一个Zuul服务器,或者选择性的打开一部分的代理功能,可以用@EnableZuulServer。任何一个在应用中申明了ZuulFilter的对象都,有@EnableZuulProxy注解的话会被自动加入,没有的话,不会被自动加入。
这种情况下,可以路由到Zuul服务的路由仍然可以通过zuul.routes.*去配置,但没有服务发现也没有代理,因此serviceId和url设置会被忽略。例如:
application.yml
zuul:
routes:
api: /api/**
会把所有/api/**的路由映射到Zuul的过滤链去。
禁用Zuul的过滤器
无论在代理模式还是服务模式下,通过Spring cloud的Zuul服务已经开启了一些ZuulFilter对象。 Zuul过滤器包可以查看启用的可用过滤器。
简单的设置zuul.
通过Sidecar支持多语言
你想在不使用jvm的语言去用Eureka,Ribbon和配置服务?Spring cloud netflix Sidecar 的想法来自于Netflix Prana项目。包含对某个服务通过一个简单的http api生成多个实例。还可以通过内置的Zuul代理来自Eureka的注册服务调用。Spring Cloud配置服务可以通过主机查看或者Zuul代理访问到。不使用jvm的语言也可以实现健康诊断,通过Sidecar向Eureka上报服务在不在线。
创建一个Spring boot应用,添加@EnableSidecar注解,可以启用Sidecar。这个注解包含@EnableCircuitBreaker, @EnableDiscoveryClient和@EnableZuulProxy。在同一个主机上也可以将非jvm应用运行为同样的应用。
通过sidecar.port和sidecar.health-uri配置到application.yml设置Sidecar。sidecar.port可以设置非jvm应用监听的端口。这也是通过Sidecar向Eureka注册服务的方式。sidecar.health-uri指定非jvm应用类似spring boot应用诊断的健康状态的可访问到的uri的路径。将会返回一下json格式的结果:
health-uri-document
{
"status":"UP"
}
这里是一个Sidecar应用的application.yml示例配置:
application.yml
server:
port: 5678
spring:
application:
name: sidecar
sidecar:
port: 8000
health-uri: http://localhost:8000/health.json
DiscoveryClient.getInstances()方法的api路径是/hosts/{serviceId}。这是一个/hosts/customer服务响应的运行在不同主机上的两个实例的例子。 (如果sidecar运行在5678端口) 通过http://localhost:5678/hosts/{serviceId}可以直接访问到这个非jvm的应用。
/hosts/customers
[
{
"host": "myhost",
"port": 9000,
"uri": "http://myhost:9000",
"serviceId": "CUSTOMERS",
"secure": false
},
{
"host": "myhost2",
"port": 9000,
"uri": "http://myhost2:9000",
"serviceId": "CUSTOMERS",
"secure": false
}
]
Zuul代理会自动为每一个知道的服务在Eureka中添加到/<serviceId>下, 因此,customers服务会在/customers路径下。(如果sidecar运行在5678端口) 通过http://localhost:5678/customers 可以直接访问到customers服务。
如果配置服务是通过Eureka注册的,可以通过Zuul代理访问到非jvm应用。 如果服务id是configserver,并且Sidecar运行在5678端口上,那可以通过http://localhost:5678/configserver访问。
非jvm的应用可以应用配置服务的功能返回YAM资料。对http://sidecar.local.spring.io:5678/configserver/default-master.yml的调用会返回这样的结果:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
password: password
info:
description: Spring Cloud Samples
url: https://github.com/spring-cloud-samples
RxJava与Spring MVC一起使用
Spring Cloud Netflix包含RxJava。 RxJava 是java方式对响应式扩展的实现:通过观察的序列形成了异步和事件驱动的编程实现。 Spring Cloud Netflix提供了从spring mvc中的返回rx.Single的对象。它还支持发送rx.Observable服务端发出的事件对象。如果你已经用RxJava构建你的api的话,这会很方便(以Feign Hystrix support为例)。
这里是一个用rx.Single的示例:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single<String> single() {
return Single.just("single value");
}
@RequestMapping(method = RequestMethod.GET, value = "/singleWithResponse")
public ResponseEntity<Single<String>> singleWithResponse() {
return new ResponseEntity<>(Single.just("single value"), HttpStatus.NOT_FOUND);
}
@RequestMapping(method = RequestMethod.GET, value = "/throw")
public Single<Object> error() {
return Single.error(new RuntimeException("Unexpected"));
}
如果你有Observable的话,而不是的rx.Single,可以用.toSingle()或者.toList().toSingle()方法。例如:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single<String> single() {
return Observable.just("single value").toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/multiple")
public Single<List<String>> multiple() {
return Observable.just("multiple", "values").toList().toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/responseWithObservable")
public ResponseEntity<Single<String>> responseWithObservable() {
Observable<String> observable = Observable.just("single value");
HttpHeaders headers = new HttpHeaders();
headers.setContentType(APPLICATION_JSON_UTF8);
return new ResponseEntity<>(observable.toSingle(), headers, HttpStatus.CREATED);
}
@RequestMapping(method = RequestMethod.GET, value = "/timeout")
public Observable<String> timeout() {
return Observable.timer(1, TimeUnit.MINUTES).map(new Func1<Long, String>() {
@Override
public String call(Long aLong) {
return "single value";
}
});
}
如果你有文件流客户端和服务端的话,服务端发出的事件是个可选项。用RxResponse.sse()可以把rx.Observable转化为Spring SseEmitter服务端发出事件的生成器。例如:
@RequestMapping(method = RequestMethod.GET, value = "/sse")
public SseEmitter single() {
return RxResponse.sse(Observable.just("single value"));
}
@RequestMapping(method = RequestMethod.GET, value = "/messages")
public SseEmitter messages() {
return RxResponse.sse(Observable.just("message 1", "message 2", "message 3"));
}
@RequestMapping(method = RequestMethod.GET, value = "/events")
public SseEmitter event() {
return RxResponse.sse(APPLICATION_JSON_UTF8, Observable.just(
new EventDto("Spring io", getDate(2016, 5, 19)),
new EventDto("SpringOnePlatform", getDate(2016, 8, 1))
));
}
Metrics: Spectator, Servo,和Atlas
当Spectator/Servo和Atlas一起使用的话,几乎可以提供实时平台的监控。A
Spectator和Servo是Netflix的metrics组合库,Atlas是metrics的时间维度系列数据的服务端。
Servo已经在Netflix中使用了好几年了仍然在用,当逐渐的被Spectator的方式慢慢替代,只在java8下正常工作。Spring Cloud Netflix对这个库都支持,但只限于java8上,推荐使用Spectator。
横向和纵向的Metrics监控
Spring Boot Actuator metrics监控只纵向的,并且 metrics监控以名字分开的。这些名字按照约定是以key/value键值对的方式设置属性名的。参考root和star-star两个服务端:
{
"counter.status.200.root": 20,
"counter.status.400.root": 3,
"counter.status.200.star-star": 5,
}
第一个metrics监控反映了单位时间内对根路径正常访问的请求数量。但如果我们有20个路径,你想知道所有路径下的正常访问量是多少该怎么办呢?纵向metrics监控支持你设置counter.status.200.的命名卡片,这样会读取这20个监控并且汇总。你还可以通过HandlerInterceptorAdapter分别对每个路径,拦截并记录类似counter.status.200.all的成功访问结果。这样话,你必须写21个不同的metrics监控。类似的,你想知道所有路径的成功请求个数是多少的话,你可以建立counter.status.2.*这样的卡片。
即便命名卡支持垂直metrics监控的服务端,命名一直性保持也是很难的。特别是在这些名称会随着时间的推移改变以及终端查询。如果,假如我们想在纵向维度上通过http添加一层监控。这样counter.status.200.root可能会counter.status.200.method.get.root,等。我们counter.status.200.*突然会失去了原来的意义。更长远的情况是,新添加的维度会和我们的基础代码不一致,某些查询也会变得不太可能。这样情况会变得无法控制。
Netflix metrics监控打上了标签(用众所周知的,维度)。每个metrics监控的都有名字,单个命名的metrics监控包含多组数据,并且key/value键值对的标签会允许更多的方便的查询。实际上,这些统计结果可以在某个特殊的标签上记录。 Netflix Servo或者Spectator记录的,对根路径的时间轴上的记录每一种状态包含4组统计数据,这个计数器和Spring Boot Actuator的计数器就是同一个计数器。当我们遇到http200和40状态的结果是,将会有8中可用的数据点:
{
"root(status=200,stastic=count)": 20,
"root(status=200,stastic=max)": 0.7265630630000001,
"root(status=200,stastic=totalOfSquares)": 0.04759702862580789,
"root(status=200,stastic=totalTime)": 0.2093076914666667,
"root(status=400,stastic=count)": 1,
"root(status=400,stastic=max)": 0,
"root(status=400,stastic=totalOfSquares)": 0,
"root(status=400,stastic=totalTime)": 0,
}
默认Metrics集合
不用其他更多配置,Spring Cloud 会自动添加Servo MonitorRegistry对象,并且开始对spring mvc的每个请求都去收集监控数据。默认情况下,一个以rest命名的Servo时间维度Metrics监控,会标签:
HTTP请求方法
HTTP状态 (例如200, 400, 500)
URI (如果uri是空的话,会是"root"),用以Atlas检查
如果请求处理发生了异常,则是异常的类名
调用者,如果请求的某个头信息匹配netflix.metrics.rest.callerHeader的话。netflix.metrics.rest.callerHeader没有默认的键。你必须在应用的属性配置中添加上,如果你想要搜集调用者的信息。
设置netflix.metrics.rest.metricName属性可以把metrics监控名称rest改为你所提供的名称。
如果spring的AOP开启了,并且org.aspectj:aspectjweaver在classpath下,Spring cloud还会收集从RestTemplate发出的请求的监控数据。以restclient命名的Servo时间维度Metrics监控,会标签:
HTTP请求方法
HTTP状态 (例如200, 400, 500), "CLIENT_ERROR":如果响应没有回复, "IO_ERROR"如果在RestTemplate方法执行过程中发生了IOException异常
URI,用以Atlas检查
客户端名称
Metrics监控集合:Spectator
需要添加spring-boot-starter-spectator去启用Spectator metrics监控集合:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-spectator</artifactId>
</dependency>
在Spectator用法里,带命名,类型标签的配置是一种计量,并且metric代表给定计量的某一时间点 的值。Spectator通过注册器创建并控制,目前有好几种实现方式。Spectator提供了4种计量方式:counter计数器, timer定时器, gauge尺度, 和distribution summary分布总结。
Spring Cloud Spectator的集成,对你来说,只需要配置一个com.netflix.spectator.api.Registry实例。确切的说,它是配置一个ServoRegistry实例,为了整合所有的REST metrics集合,并且导出这些metrics集合到Atlas服务端在Servo api接口。 实际情况下,这意味着你的代码包含Servo监控器和Spectator计量的混合,会被挂在Spring Boot Actuator MetricReader实例下,并且都会挂到Atlas服务端。
Spectator Counter计数器
计数器是用来计算事件发生的次数。
// create a counter with a name and a set of tags
Counter counter = registry.counter("counterName", "tagKey1", "tagValue1", ...);
counter.increment(); // increment when an event occurs
counter.increment(10); // increment by a discrete amount
计数器会记录某个时间线的统计。
Spectator timer计时器
计时器是用来计算事件占用的时间长短。 Spring Cloud自动记录了sprimg mvc每个请求,和某些RestTemplate请求的占用时长,用于在面板上展示各个请求的时间延迟。
Request Latency
// create a timer with a name and a set of tags
Timer timer = registry.timer("timerName", "tagKey1", "tagValue1", ...);
// execute an operation and time it at the same time
T result = timer.record(() -> fooReturnsT());
// alternatively, if you must manually record the time
Long start = System.nanoTime();
T result = fooReturnsT();
timer.record(System.nanoTime() - start, TimeUnit.NANOSECONDS);
计时器同时记录4类统计结果:数量,最大值,总和,以及总时间。数量统计在某个时间点的结果和计数器的结果一致,每次都调用increment()增加一次用来及时,把数量和时间分开去统计的结果没有太大的意义。
对于长时间的操作,提供了LongTaskTimer。
Spectator Gauge压力
Gauge压力是用来测量并发值,例如运行状态的请求队列的大小或者线程数量。由于Guage压力是通过抽样获取的,无法提供信息告诉你这些值是如何变化的。 通常一开始用一个id初始化的时候,在guage中注册一次,需要抽样的对象引用,包含一个可以计算对象数量的函数,就可以使用了。这个对象的引用是分别传入的,Spectator注册器对它们都是弱引用。以下会展示错误的使用情况下,会导致内存泄露:
// the registry will automatically sample this gauge periodically
registry.gauge("gaugeName", pool, Pool::numberOfRunningThreads);
// manually sample a value in code at periodic intervals -- last resort!
registry.gauge("gaugeName", Arrays.asList("tagKey1", "tagValue1", ...), 1000);
Spectator分布能力总结
分布总结是用来记录事件的分布能力。和计时器类似,但更广泛的是,不一定的一段时间的大小。例如,分布总结可以是命中服务的请求的负载数量。
// the registry will automatically sample this gauge periodically
DistributionSummary ds = registry.distributionSummary("dsName", "tagKey1", "tagValue1", ...);
ds.record(request.sizeInBytes());
Metrics监控集合:Servo
警告:如果你的代码是运行在java8上的,请用Spectator替换Servo,因为长期考虑中希望使用Spectator替换Servo的。
在Servo用法里,带命名,类型标签的配置是一种计量,并且metric代表给定计量的某一时间点 的值。Servo监控器和Spectator的计量逻辑上是一样的。用MonitorRegistry来创建并且控制Servo监控器。除了以上的警告,Servo的监控器比Spectator有更宽泛的监控选项。
spring cloud提供com.netflix.servo.MonitorRegistry实例注入的方式整合配置。你开始建立好Monitor类型后,整个监控的记录结果和Spectator类似。
创建Servo的监控器
如果你使用spring cloud提供的MonitorRegistry实例(例如,DefaultMonitorRegistry),Servo提供了获取计数器和计时器的示例类。这些类确保为每个名称和标签的结合只创建一个监控器。 要手动创建Servo监控器的话,特别未某些简单的方法的监控器类型,通过实例化合适的类型提供MonitorConfig实例。
MonitorConfig config = MonitorConfig.builder("timerName").withTag("tagKey1", "tagValue1").build();
// somewhere we should cache this Monitor by MonitorConfig
Timer timer = new BasicTimer(config);
monitorRegistry.register(timer);
Metrics监控服务端:Atlas
Atlas是netflix希望作实时操作来监控管理多维时间系列数据的库。Atlas内存数据存储特性,使得它能很快的搜集并发布很多的监控数据。 Atlas是操作智能的。类似商业智能是用来分析业务交易随着时间变化的发展趋势,操作智能是用来一张系统中正在发生着什么的图片。 Spring Cloud提供了spring-cloud-starter-atlas包含了所有你需要的依赖。因此只需要用@EnableAtlas注解到您的spring boot应用上,并且配置netflix.atlas.uri属性指定到Atlas服务运行的uri地址上。
全局标签
Spring Cloud允许你向Atlas服务端任意一个监控添加标签。全局的标签通过应用名,环境,区域等可以用来区分监控。
每个实现了AtlasTagProvider的对象都可以添加到全局标签。
@Bean
AtlasTagProvider atlasCommonTags(
@Value("${spring.application.name}") String appName) {
return () -> Collections.singletonMap("app", appName);
}
使用Atlas
要启动一个内存运行中的标准Altas实例:
$ curl -LO https://github.com/Netflix/atlas/releases/download/v1.4.2/atlas-1.4.2-standalone.jar
$ java -jar atlas-1.4.2-standalone.jar
注意:一个r3.2xlarge (61GB RAM)的服务器上运行一个内存标准的Atlas可以处理每分钟将近2亿的统计数据打开一个6小时的窗口。
你一运行就能收集到处理过的统计结果,通过列出所有的标签可以验证你的设置是否正确:
$ curl http://ATLAS/api/v1/tags